dimension

What is dimension in data warehousing?
In data warehousing, a dimension is a collection of reference information that supports a measurable event, such as a customer transaction. In this context, events are referred to as "facts." Dimensions provide the details necessary to understand and analyze a set of related facts.
For example, a data warehouse might include a set of facts about a company's product sales. Each sale is a fact that reflects what product was sold, when it was sold, who bought the product, how much it cost and other relevant information.
Dimensions support these facts by providing the background information needed to understand each sale. The data warehouse might include dimensions about products, customers, sales territories, and the dates that various events took place, such as when the product was ordered or shipped.
Dimensions categorize and describe facts and their measures in ways that support meaningful answers to business queries. They serve as the fundamental building blocks for developing a data model that facilitates the efficient analysis of historical data. To this end, dimensions provide the structural underpinnings necessary to make sense of a collection of facts.
What are dimensions and facts in a data warehouse?
A data warehouse organizes dimensions into related attributes that are implemented as columns in dimension tables. For example, a customer dimension might include attributes such as first name, last name, email address, birth date and gender. Meanwhile, a product dimension might include attributes such as product name, product description and product type.
The following figure (1) shows a simple data warehouse that incorporates these two dimensions and adds the territory and date dimensions. The fact table (factSales) consolidates all the information about the sales facts by referencing the related dimensions.
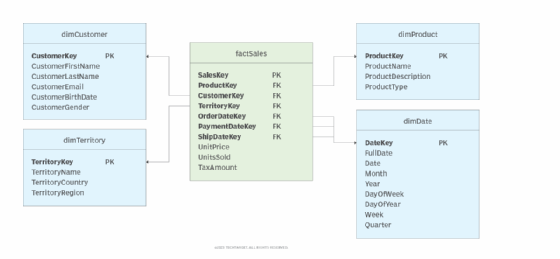
A dimension table has a primary key column that uniquely identifies each dimension record (row). The fact table uses the key to reference the data within the dimension table. In this way, the facts have the information they need to provide a complete picture of each event.
Data in the fact table can be filtered and grouped ("sliced and diced") by various combinations of dimensional attributes. For example, someone can query the sales fact and dimensions for an answer to the question: "How many male customers in Washington and Oregon between ages 19 through 25 purchased rain jackets during the last week of October 2022?" To retrieve this information, the query would join the data in the fact table to the data in the referenced dimensions: customer, territory, product and date.
Many dimensions contain a hierarchy of attributes that support drilling up and down. For instance, the date dimension in the example above contains the hierarchy year > quarter > month > week > date. A report displaying the number of sales in 2022 by week could drill up to display sales by month or drill down to the individual dates.
Related dimensions in a data warehouse are typically laid out in a star schema or snowflake schema, with the fact table at the center. The figure above shows a small star schema whose central fact table joins to multiple related dimension tables. The data in the dimensions is denormalized to avoid the query overhead that comes with a highly normalized schema. Someone can query the fact table and dimension tables without having to join to any tables beyond those core dimension tables, helping to reduce query complexity and increase performance.
The snowflake schema extends the star schema by joining one or more of the dimension tables to other dimensions, in effect normalizing the dimension tables. For instance, the dimTerritory table in the above example might be normalized by moving the country and region data to separate dimensions to better serve complex business needs. In that case all three dimensions could be joined through their primary keys, as shown in the following figure (2).
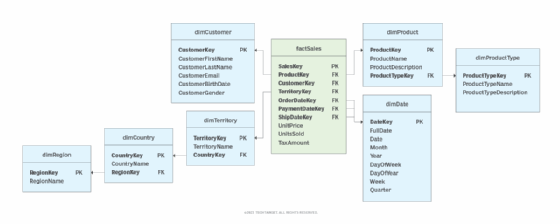
The schema in the figure also normalizes the dimProduct dimension by moving the product type data to a separate table. Some snowflake schemas might also normalize the dimDate dimension, depending on the specific business requirements. Because the snowflake schema normalizes the data, there is less repetitive data and therefore less storage is required. However, querying the data becomes more complex because there are a greater number of joins.
What are the types of dimensions in a data warehouse?
Data warehouse dimensions are often categorized by type, based on the role they play within the data warehouse. The following dimensions represent some of the more common types:
- Conformed dimension is a dimension that can be referenced by multiple fact tables and that has the same meaning to every fact that references the dimension. For instance, the customer and product dimensions in the examples above could serve as conformed dimensions if they have the same meaning to any fact tables in the data warehouse that reference them.
- Role-playing dimension is a dimension that a fact can use for multiple purposes. For instance, the sales fact in the example above uses the date dimension for the order date, payment date and shipment date. As a result, the date dimension can be considered a role-playing dimension.
- Slowly changing dimension is a dimension whose data changes steadily over time. For example, the data in a customer dimension will slowly change as customers update their addresses and contact information. Slowly changing dimensions are often further classified by type, based on how historical data is handled.
- Junk dimension is a dimension that consolidates different types of attributes that don't require their own dimensions. For example, a junk dimension might be used for flags, Boolean search values or other attributes that don't fit neatly into more focused dimensions such as products or customers.
- Degenerate dimension is a dimension that is logically formed from attributes in a fact table with no associated dimension tables. For example, a sales fact table might include data such as invoice numbers or order numbers. This data would form a degenerate dimension.
These are neither the only possible types of dimensions in a data warehouse, nor are they the only way to classify dimensions. For example, they might be categorized by whether they change or how frequently they change, such as classifying them as static or as slowly changing.
Although dimensions play a vital role in data warehouses, they also play a role in other applications. For example, dimensions are used in online analytical processing (OLAP) cubes and in business intelligence (BI) and business analytic (BA) applications.
Learn about the differences between a data lake versus data warehouse and evaluate data warehouse deployment options and use cases. Also explore the top five elements needed for a successful data warehouse.




